I’ve been working with Amazon’s Alexa & the Echo family of devices for the past several months and have created a couple of pretty useful and/or interesting skills. The first one I liked well enough to publish was QOTD, a Quote of the Day app that retrieves and reads a random quote per request. The second was Master Control Program, which enabled voice control of my home renewable energy system’s various inputs and controls.
I recently tweeted (@mkheck) a quote from the QOTD skill and got a bit of inspiration from a friend:
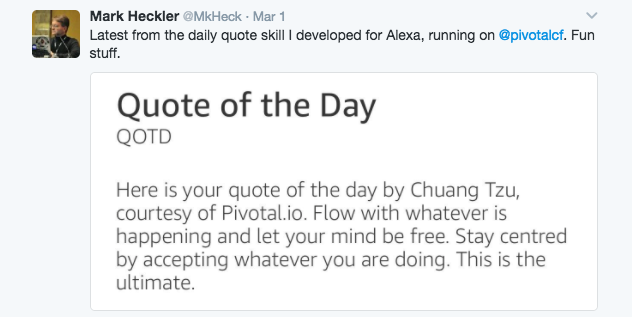
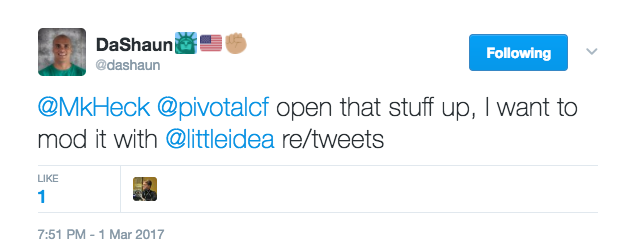
A bit of explanation may be in order. 🙂
Inspiration
DaShaun got me thinking…there are some people who offer some excellent insights via their public Twitter accounts. He even pointed out one of those: Andrew Clay Shafer, a.k.a. “@littleidea”. Full disclaimer: Andrew also happens to lead our advocacy team at Pivotal. He says good things, and if you aren’t already following him, you should. Go. Now. 🙂

As DaShaun noted though, it might also be nice to request a random tweet from someone else. So whatever came of this, it should be flexible.
How to develop an Alexa skill
Overview
First things first: we can use AWS lambdas or provide our own cloud-based application, provided it responds to the appropriate requests appropriately. What does this mean?
- You must implement the Speechlet API. Amazon makes this easy for Python, Node.js, & Java by providing libraries with the required functionality.
- You must accept requests on an endpoint that you specify and provide correctly-formed responses.
That’s largely it. Of course, you’ll need an Amazon developer account. Sign up here to get started.
More details, please
This isn’t the only way to build a skill, but I’ve assembled inputs from several others and honed them in ways that make sense to me. Feel free to adapt/adjust as you see fit, and please share! Happy to alter my approach if yours makes life better/easier. 🙂
- Create a “shell” Spring Boot app at https://start.spring.io, adding the Web dependency (and Lombok if you’re so inclined), downloading & unzipping the project and opening it in your favorite IDE
- Add the following dependency to your pom.xml file (you aren’t a Gradle hipster, are you??!?!)
<dependency> <groupId>org.twitter4j</groupId> <artifactId>twitter4j-core</artifactId <version>[4.0,)</version> </dependency>
<dependency>
<groupId>com.amazon.alexa</groupId>
<artifactId>alexa-skills-kit</artifactId>
<version>1.2</version>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
</exclusions>
</dependency>
NOTE 1: Twitter4j included for the Tweet Retriever project, may not apply to yours.
NOTE 2: The exclusion is currently necessary to avoid conflicts with dependencies included by Spring Boot’s starters.
- Create a mechanism that will implement your desired “back end” functionality: retrieving a tweet, requesting weather from a public REST API, etc.
- (Optional, strictly speaking) Create a REST endpoint you can use to test via web browser (old school text) 😉
- To save yourself a lot of time & potential frustration, do the previous step. Then test. Extensively. Don’t continue until everything works the way you would like as a “plain old web service”. Once that works, then proceed to the next step.
- Create an Intent Schema (JSON format) as required by the Alexa service. Within this schema, you’ll want/need to specify what intents your app will recognize and what slots (variables) are allowed or expected for each intent.
- If you specify a slot, you’ll likely have a list of expected values for that slot (note that this is not a closed list per Amazon, but “more like guidelines”, for better & worse). I find it helpful to specify those slot values in separate files and store them (along with other textual inputs such as the Intent Schema & sample utterances Alexa uses for voice recog) with this project under a speechAssets directory in the project’s resources. Please refer to the project repo (link at bottom) for more information.
- Create Sample Utterances Alexa will use to help guide its voice recognition, leveraging any slots you’ve defined in your Intent Schema. For example, in my Random Tweet skill, I define the following slot:
{
"intent": "TweetIntent",
"slots": [
{
"name": "Action",
"type": "LIST_OF_ACTIONS"
}
]
}
I specify valid actions as:
get give play provide show read
To tie it together, one of my sample utterances is:
TweetIntent {Action} a tweet
The end result is that one way to activate the skill (once all steps are completed and the application is deployed) is with the following syntax:
"Alexa, ask Tweet Retriever to {get|give|play|provide|show|read} a tweet"
- Create a Speechlet that implements Alexa’s Speechlet interface
- Register that Speechlet (servlet) with your application, providing an endpoint (see above) with which Alexa will interact
- Deploy the application to your cloud provider (Cloud Foundry, of course!)
- Create the skill in the Amazon (Alexa) developer portal and make note of the Application Id Amazon assigns in the Skill Information page
NOTE: Be sure to include the endpoint address you specified when registering the speechlet in your application
- Set your application’s required env vars (including the Application Id above), then restart the application to allow it to incorporate the updated values
- From the Test page of the Skills portal, test the skill by invoking with textually and note the results
- Next, test using your Echo device. This step is critical because it adds the voice recognition/parsing engine to the mix and often exposes issues that text-based invocations don’t.
- If everything works as desired and you would like to share your skill with a larger community (Optional), publish your skill. You’ll need to provide a few additional bits of information & a couple icons, and it will need to be tested and verified by Amazon prior to it being published. If it fails, Amazon is quite good about providing feedback over any small items you missed and suggested remedies. Lather, rinse, repeat until successful. 😉
Caveats
This project is very early stage and thus very rough, so please keep the following things in mind:
- This is version 0.1. It will change, it will improve. It’s an MBVP, a Minimum Barely Viable Product.
- Alexa VR is unkind at times. 😉 For this 0.1 release, I incorporated a couple hacks to get more reliable results for certain Twitter handles:
- For Andrew Clay Shafer’s Twitter handle (a compound word with two dictionary words, “little” & “idea”)
- For my Twitter handle (a non-word that is stated as a combination of letters & a “word”, “M K Heck”). Twitter handles consisting of a single dictionary word pose no problem for Alexa/Twitter
- I included Andrew’s handle per DaShaun’s request (see above)…and mine because I didn’t want to creep on Andrew by issuing repeated calls to Alexa while testing. 🙂 Feel free to adjust for your circumstances, if so desired.
For more Information
Get Tweet Retriever’s ax-random-tweet code here, check it out, and if you’re so inclined, submit a pull request! And thanks for reading.
Cheers,
Mark

Related Posts:
Tags: alexa, Cloud, Cloud Foundry, random tweet, Spring Boot, tweet, Twitter, voice