As you begin to divide conglomerate functionality into discrete, decoupled microservices, you introduce a number of opportunities and challenges into your system(s). The opportunities are often well-known, including (and especially!) development velocity, fidelity/fit (functionality matches requirements), scalability, and a host of other “ilities”.
Challenges also exist of course, including the question of how to gain visibility into end-to-end interactions involving multiple microservices across process and network boundaries. Spring Cloud Sleuth provides a lightweight, configurable, and easy way to begin capturing trace information within your distributed system.
In 2012, Twitter created Zipkin during their first Hack Week, based upon the Dapper paper.
Briefly, an entire end-to-end interaction that completes a request cycle (regardless of transport/mechanism) is referred to as a “trace”, and each trace consists of multiple “spans” connecting the endpoints of each hop. From the Spring Cloud Sleuth project page:
A Span is the basic unit of work. For example, sending an RPC is a new span, as is sending a response to an RPC. Span’s are identified by a unique 64-bit ID for the span and another 64-bit ID for the trace the span is a part of. Spans also have other data, such as descriptions, key-value annotations, the ID of the span that caused them, and process ID’s (normally IP address). Spans are started and stopped, and they keep track of their timing information. Once you create a span, you must stop it at some point in the future. A set of spans forming a tree-like structure called a Trace. For example, if you are running a distributed big-data store, a trace might be formed by a put request.
Sometimes within the Spring space, you hear about Sleuth and Zipkin within the same discussion, often within the same breath…which understandably can result in a bit of confusion on the listener’s part. Without diving too far down the rabbit hole, Sleuth provides the means to instrument your Spring Boot/Spring Cloud applications; Zipkin can take that data and provide a means to monitor and evaluate it. Zipkin provides numerous integrations, but of course, you can also use other log monitoring & management tools to collect and analyze that vital data.
Minimum Viable Product
This post focuses upon Sleuth and provides a quick on-ramp to getting started capturing basic information for each span. To do that, I’ve created these two projects that allow us to quickly add trace & span (& more) information to our interactions and verify it in our logs.
Creating a provider service
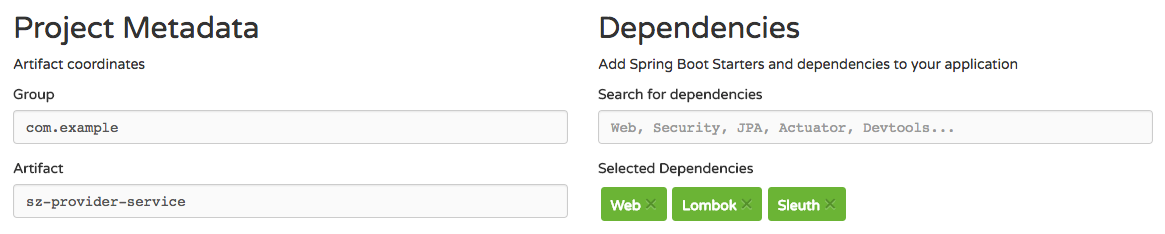
Starting at the Spring Initializr, I added the following dependencies to a project and named the artifact sz-provider-service:
(click/tap to enlarge)
After generating the project and downloading, extracting, and opening it in our IDE, we see the selected dependencies in our Maven pom:
Or if using Gradle, build.gradle:
To provide better context within our logs for our tracing data, we’ll add the following entry to our application.properties file:
spring.application.name=sz-provider-service
For this example, we’ll create a very simple RestController so we have something in our provider microservice to contact from a consumer service. Here is the entirety of the relevant code:
The only thing of particular note is the @Log statement. Lombok provides this capability to reduce the usual boilerplate code required to get a logger via LogFactory.
Creating a consumer service
For the purpose of this introduction, little changes between provider and consumer project configuration & code. Here are the exceptions:
Revisiting the Spring Initializr, we change the artifact name to sz-consumer-service, keeping the same dependencies
We add the following entries to our consumer microservice’s application.properties file:
NOTE: We’re running the provider on port 8080 (Tomcat’s default port), so we change our consumer service’s port to 8081 to avoid conflict.
This is the code for our consumer:
The same note about Lombok’s @Log applies here as well, of course.
The results
Running the two applications, we can now access the consumer’s endpoint from httpie, cURL, or a browser:
Doing so results in the following log entries from our consumer service:
And our provider service:
Examining our log entries for both services (above), we see that Spring Cloud Sleuth has placed our spring.application.name (as designated in each service’s application.properties), the appropriate trace id, and the span id specific to this hop within the logged information.
Summary
Of course, Sleuth captures much more data and allows for extensive customization (including enabling additional elements you specify to be captured, adjusting sampling rates, & more), and Zipkin remains a topic for another day. But this post should have provided a quick springboard (!) into using Spring Cloud Sleuth for better insight into your microservices-based system of systems.
I’ve been working with Amazon’s Alexa & the Echo family of devices for the past several months and have created a couple of pretty useful and/or interesting skills. The first one I liked well enough to publish was QOTD, a Quote of the Day app that retrieves and reads a random quote per request. The second was Master Control Program, which enabled voice control of my home renewable energy system’s various inputs and controls.
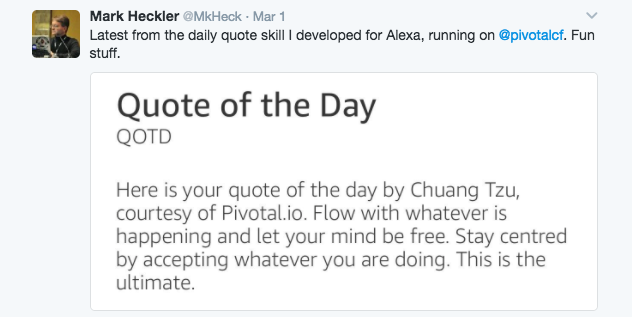
I recently tweeted (@mkheck) a quote from the QOTD skill and got a bit of inspiration from a friend:
A bit of explanation may be in order. 🙂
Inspiration
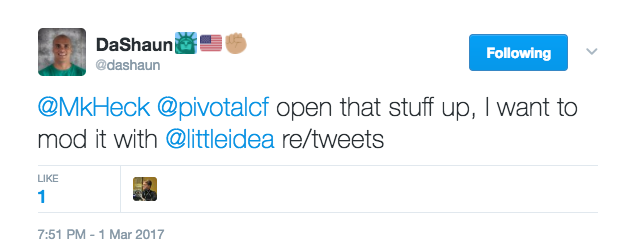
DaShaun got me thinking…there are some people who offer some excellent insights via their public Twitter accounts. He even pointed out one of those: Andrew Clay Shafer, a.k.a. “@littleidea”. Full disclaimer: Andrew also happens to lead our advocacy team at Pivotal. He says good things, and if you aren’t already following him, you should. Go. Now. 🙂
As DaShaun noted though, it might also be nice to request a random tweet from someone else. So whatever came of this, it should be flexible.
How to develop an Alexa skill
Overview
First things first: we can use AWS lambdas or provide our own cloud-based application, provided it responds to the appropriate requests appropriately. What does this mean?
You must implement the Speechlet API. Amazon makes this easy for Python, Node.js, & Java by providing libraries with the required functionality.
You must accept requests on an endpoint that you specify and provide correctly-formed responses.
That’s largely it. Of course, you’ll need an Amazon developer account. Sign up here to get started.
More details, please
This isn’t the only way to build a skill, but I’ve assembled inputs from several others and honed them in ways that make sense to me. Feel free to adapt/adjust as you see fit, and please share! Happy to alter my approach if yours makes life better/easier. 🙂
Create a “shell” Spring Boot app at https://start.spring.io, adding the Web dependency (and Lombok if you’re so inclined), downloading & unzipping the project and opening it in your favorite IDE
Add the following dependency to your pom.xml file (you aren’t a Gradle hipster, are you??!?!)
NOTE 1: Twitter4j included for the Tweet Retriever project, may not apply to yours.
NOTE 2: The exclusion is currently necessary to avoid conflicts with dependencies included by Spring Boot’s starters.
Create a mechanism that will implement your desired “back end” functionality: retrieving a tweet, requesting weather from a public REST API, etc.
(Optional, strictly speaking) Create a REST endpoint you can use to test via web browser (old school text) 😉
To save yourself a lot of time & potential frustration, do the previous step. Then test. Extensively. Don’t continue until everything works the way you would like as a “plain old web service”. Once that works, then proceed to the next step.
Create an Intent Schema (JSON format) as required by the Alexa service. Within this schema, you’ll want/need to specify what intents your app will recognize and what slots (variables) are allowed or expected for each intent.
If you specify a slot, you’ll likely have a list of expected values for that slot (note that this is not a closed list per Amazon, but “more like guidelines”, for better & worse). I find it helpful to specify those slot values in separate files and store them (along with other textual inputs such as the Intent Schema & sample utterances Alexa uses for voice recog) with this project under a speechAssets directory in the project’s resources. Please refer to the project repo (link at bottom) for more information.
Create Sample Utterances Alexa will use to help guide its voice recognition, leveraging any slots you’ve defined in your Intent Schema. For example, in my Random Tweet skill, I define the following slot:
To tie it together, one of my sample utterances is:
TweetIntent {Action} a tweet
The end result is that one way to activate the skill (once all steps are completed and the application is deployed) is with the following syntax:
"Alexa, ask Tweet Retriever to {get|give|play|provide|show|read} a tweet"
Create a Speechlet that implements Alexa’s Speechlet interface
Register that Speechlet (servlet) with your application, providing an endpoint (see above) with which Alexa will interact
Deploy the application to your cloud provider (Cloud Foundry, of course!)
Create the skill in the Amazon (Alexa) developer portal and make note of the Application Id Amazon assigns in the Skill Information page
NOTE: Be sure to include the endpoint address you specified when registering the speechlet in your application
Set your application’s required env vars (including the Application Id above), then restart the application to allow it to incorporate the updated values
From the Test page of the Skills portal, test the skill by invoking with textually and note the results
Next, test using your Echo device. This step is critical because it adds the voice recognition/parsing engine to the mix and often exposes issues that text-based invocations don’t.
If everything works as desired and you would like to share your skill with a larger community (Optional), publish your skill. You’ll need to provide a few additional bits of information & a couple icons, and it will need to be tested and verified by Amazon prior to it being published. If it fails, Amazon is quite good about providing feedback over any small items you missed and suggested remedies. Lather, rinse, repeat until successful. 😉
Caveats
This project is very early stage and thus very rough, so please keep the following things in mind:
This is version 0.1. It will change, it will improve. It’s an MBVP, a Minimum Barely Viable Product.
Alexa VR is unkind at times. 😉 For this 0.1 release, I incorporated a couple hacks to get more reliable results for certain Twitter handles:
For Andrew Clay Shafer’s Twitter handle (a compound word with two dictionary words, “little” & “idea”)
For my Twitter handle (a non-word that is stated as a combination of letters & a “word”, “M K Heck”). Twitter handles consisting of a single dictionary word pose no problem for Alexa/Twitter
I included Andrew’s handle per DaShaun’s request (see above)…and mine because I didn’t want to creep on Andrew by issuing repeated calls to Alexa while testing. 🙂 Feel free to adjust for your circumstances, if so desired.
For more Information
Get Tweet Retriever’s ax-random-tweet code here, check it out, and if you’re so inclined, submit a pull request! And thanks for reading.
Or “How to build a portable self-powered, self-licking ice cream cone.” 😀
Several years ago, I started building what I referred to affectionately as a self-licking ice cream cone: a Renewable Energy (RE) system that powered the same IoT system that monitored it. I’ve given several talks about this system, both its hardware and its software stack, and there are so many useful (and scalable) lessons I’ve learned that I really enjoy sharing. Still learning those lessons too, btw.
Recently, Stephen Chin asked me if I could put together a portable RE IoT system to demo in the MakerZone at JavaOne this year. If a picture is worth a thousand words, a fully-built and on-premises demo must be worth at least a million, right? The idea intrigued me. Could I create a 100% fully-capable representation of a (my) real working system that would be small enough to transport to conferences and meaningful for attendees to see? Yes…yes, I thought I could. 🙂
It has been a lot of work fun!
There is much to tell, but we’ll stick to the high points for this post. More to follow.
Hardware List and Related Observations
For the portable configuration, here is the hardware I used:
One (1) 50W, 12V photovoltaic (PV) panel, bought via ebay
** I was able to use solar charge controllers for both solar/PV and wind inputs because the wind turbine I selected produces 12V DC power (vs. the AC power output of many turbines) and has a blocking diode to prevent overspeeding, and thus turbine damage. These charge controllers also have load connectors, to which I attached lamps to maintain loads on the inputs, further reducing potential for overspeeding.
This configuration closely follows my permanent installation at my house, albeit at a much smaller scale. For transportability, I’m using only a single 18Ah 12V deep cycle battery instead of several larger-capacity 12V deep cycle batteries wired in parallel to form an energy storage array. And input sensors have been reduced from a full weather station providing temperature, humidity, rainfall, wind speed & direction, ambient lighting, and atmospheric pressure readings to (for the demo system) temperature and humidity. Power readings are comparable for both systems, although I’m using a separate INA219 sensor on the demo system vs. integrated power sensors in the permanent system’s weather circuitry. And my portable system has no actuators to open windows in my power-generation building like my permanent system does. Since the demo system is fully visible to viewers, there was no need to configure a camera for visual observation/checks as I did at home. In actuality, there are few substantive differences between my 24/7/365 production system and this portable demo. 🙂
One nice feature of this portable rig: as configured, it produces far more energy than it consumes, even with a fan providing the “wind” and venue lighting providing the “sun”. Power won’t be a problem.
Software and Related Observations
The software stack for the demo system is nearly identical to that of the production system, with minor changes being made to accommodate the minor differences in attached sensors and physical devices.
I developed software for the Arduino microcontroller to run in Autonomous Mode using sensible defaults, turning on heat when ambient temperature inside the power-generation building is too low, turning on a cooling fan when it’s too hot, and opening windows on opposite sides of the building when temps climb and no rain is present (no windows in the demo config, of course). The Arduino represents an IoT endpoint that regularly (1x/second) polls attached sensors, assembles their readings, and sends them “upstream” to the IoT gateway. It also processes any inputs received from the gateway and acts accordingly; if it receives a command to switch to Manual Override, the software then accepts and processes any subsequent (validated) commands from the gateway until directed to resume with Autonomous Mode.
For the IoT gateway, I used Linux and Java SE Embedded to create a secure and standards-based stack. Raspbian Linux allows me to use utilities like ssh and vnc and to set up startup scripts for the demo config…and since it ships with Java SE Embedded, I have easy access to developer tool support and libraries for everything from RESTful web services to Websocket, which I use for system/cloud communication. I used the JSSC (Java Simple Serial Connector) library to create a wired connection from gateway to endpoint, Pi to Arduino, establishing a reliable comm link within the remote IoT system.
IoT systems are great! But without a way to communicate with, control, and harvest meaningful data from those systems, their usefulness is severely constrained. To unleash the full value of an IoT system, you need the cloud. I used Java SE, Spring Boot, and Spring Cloud OSS to do the heavy lifting with an HTML5/JS user interface, all running on Pivotal Cloud Foundry. I’m still tweaking and expanding it (in my copious spare time 😉 ), but it’s effectively feature-complete…and with only minor differences (to accommodate the sensor/device differences) between the permanent and demo systems.
And…action!
More to Come
Come see me at JavaOne! This will be up and running in the MakerZone all week, so stop by to see it and chat with the crew there. If you have any questions, comments, or feedback of any kind, please ping me on Twitter at @MkHeck or leave a comment below. Hope to see you there!
I’ve only been working with Pivotal Cloud Foundry since September 2015, but I’ve learned a great deal about it since then. I also realize there is much (much much) more to learn! The world doesn’t stand still, after all, and there are many stones I’ve yet to turn.
Sometimes I revisit something small-but-useful that I discovered long ago that I didn’t take the time to share at the time. I intend to be better about that, beginning now. If this is something you use frequently, please disregard; if there is something you use in lieu of this tip or any other, please share. 😉
Anyway, many times when deploying an application to Cloud Foundry, you will want to generate a unique URL to avoid “collisions”, i.e. attempting to reuse an in-use URL. In the past, you would insert a ${random-word} Expression Language, er, expression to do this, but at some point, the preferred approach changed. To accomplish this now, simply add random-route: true to your application’s manifest.yml file. It should look something like this:
This directs Cloud Foundry to generate a couple of words randomly and append them to your application name with hyphens, resulting in a URL that looks something like https://example-app-saprophagous-unkindliness.cfapps.io.
You can also use the command line option –random-route.